[Swift, MLModel] Segmentation을 통해 알아보는 Vision 및 CoreML 프레임워크
이번 포스트에서는 iOS에 있는 Vision기술중 하나인 Segmentation기술을 알아봄과 동시에, Vision API 및 CoreML프레임워크에 관해서 알아볼 예정입니다.
WWDC2023 살펴보기
이번 WWDC2023에서 Segmentation관련해서 새롭게 발표한 것들이 많았습니다.
그 중에 하나가 누끼기능이 있습니다.
누끼 이미지
iOS17 누끼기능 (테두리에 이펙트 생김..)
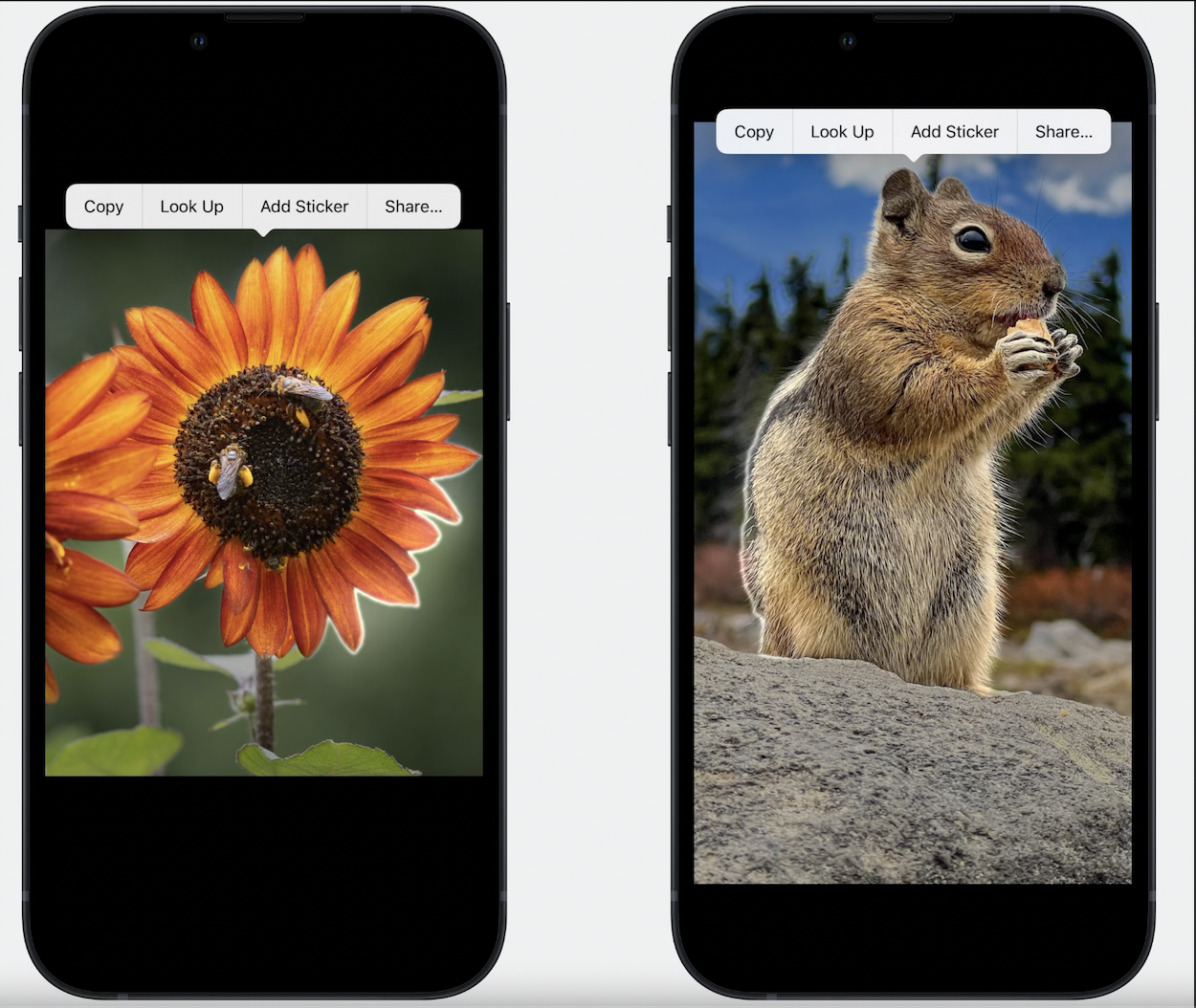
다음의 WWDC2023 영상을 보면 VisionKit과 Vision API를 이용해서 누끼기능을 구현할 수 있다고 합니다.
(VisionKit은 Vision의 맛보기 API?, Vision API를 사용하면 좀 더 고급기능 사용가능)
Lift subjects from images in your app | WWDC2023
사실 누끼기능은 iOS16에 이미 나온 기능으로 다음과 같이 정교하게 가능 물채를 감지하여 누끼를 따줬습니다.
iOS16에서 누끼 기능


iOS17의 새로운 누끼를 자세히 살펴보면 ‘Look up’, ‘Add Sticker’가 옵션이 추가되어 있음을 알 수 있습니다.
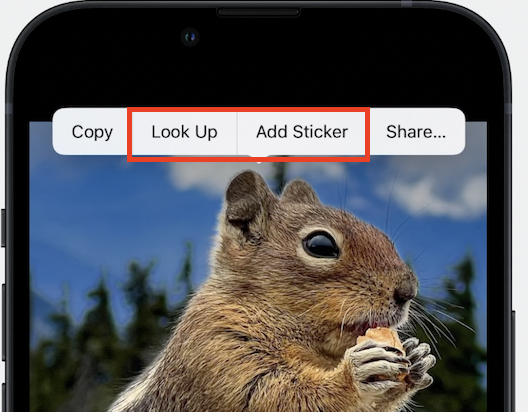
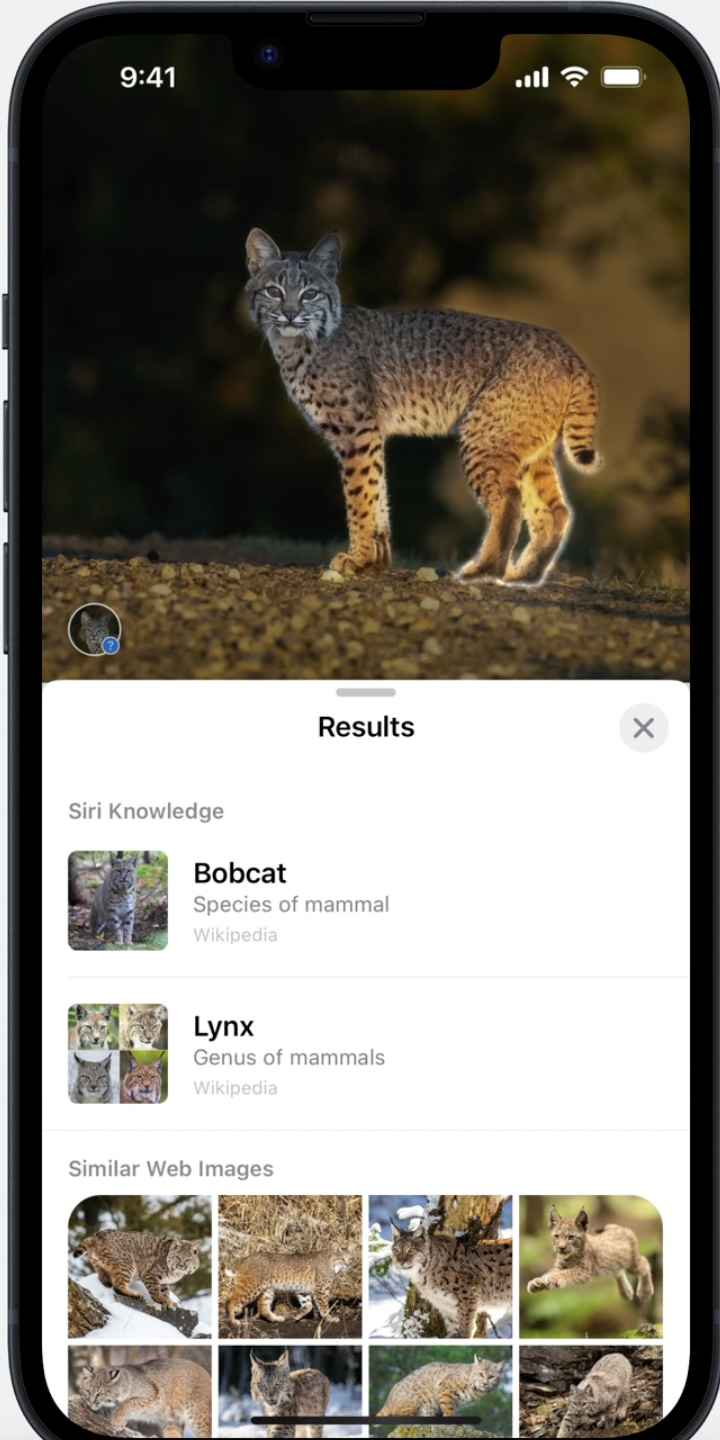
‘Look up’옵션의 경우 다음과 같이 물채를 감지하여, 분류해주는 기능입니다. 해당기능은 Segmentation + Classifier 가 합쳐진 기능인 것 같다. 해당 누끼이미지와 비슷한 이미지를 웹에서 검색해주는 기능도 가능한 것 같습니다.

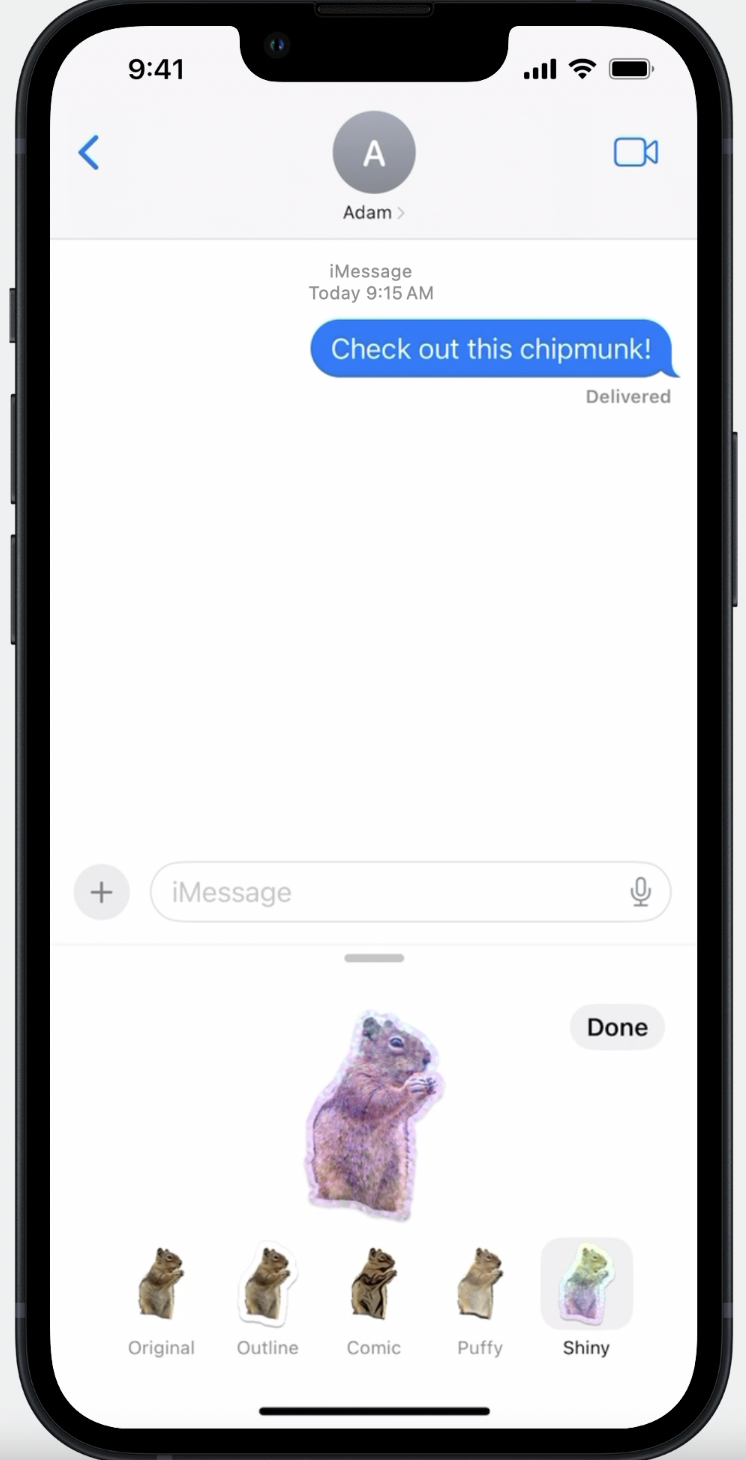
‘Add Sticker’옵션의 경우 누끼를 딴이미지를 반짝임, 푹신함 등과 같은 재미있는 효과가 있는 스티커를 만들어주는 기능이라고 합니다.
Person Segmentation
WWDC2023에 Segmentation관련 추가된 기능이 또 있는데, Person instance Segmentation기능입니다.

사실, Vision API | Apple Developer를 살펴 보면 Vision에서 이미 iOS15부터 이미 해당 Person Segmentation 기능을 제공해 주고 있었습니다.
하지만 차이점이 있다면, 기존 Person Segmentation의 경우는 시맨틱 세그멘테이션(Semantic Segmentation)으로 각각의 인스턴스(사람)을 구별하지 못했다면, 이번에는 인스턴스 세그멘테이션(Instance Segmentation)으로 객체단위를 넘어서 각각의 인스턴스를 구분하여 다룰 수 있다는 점입니다.
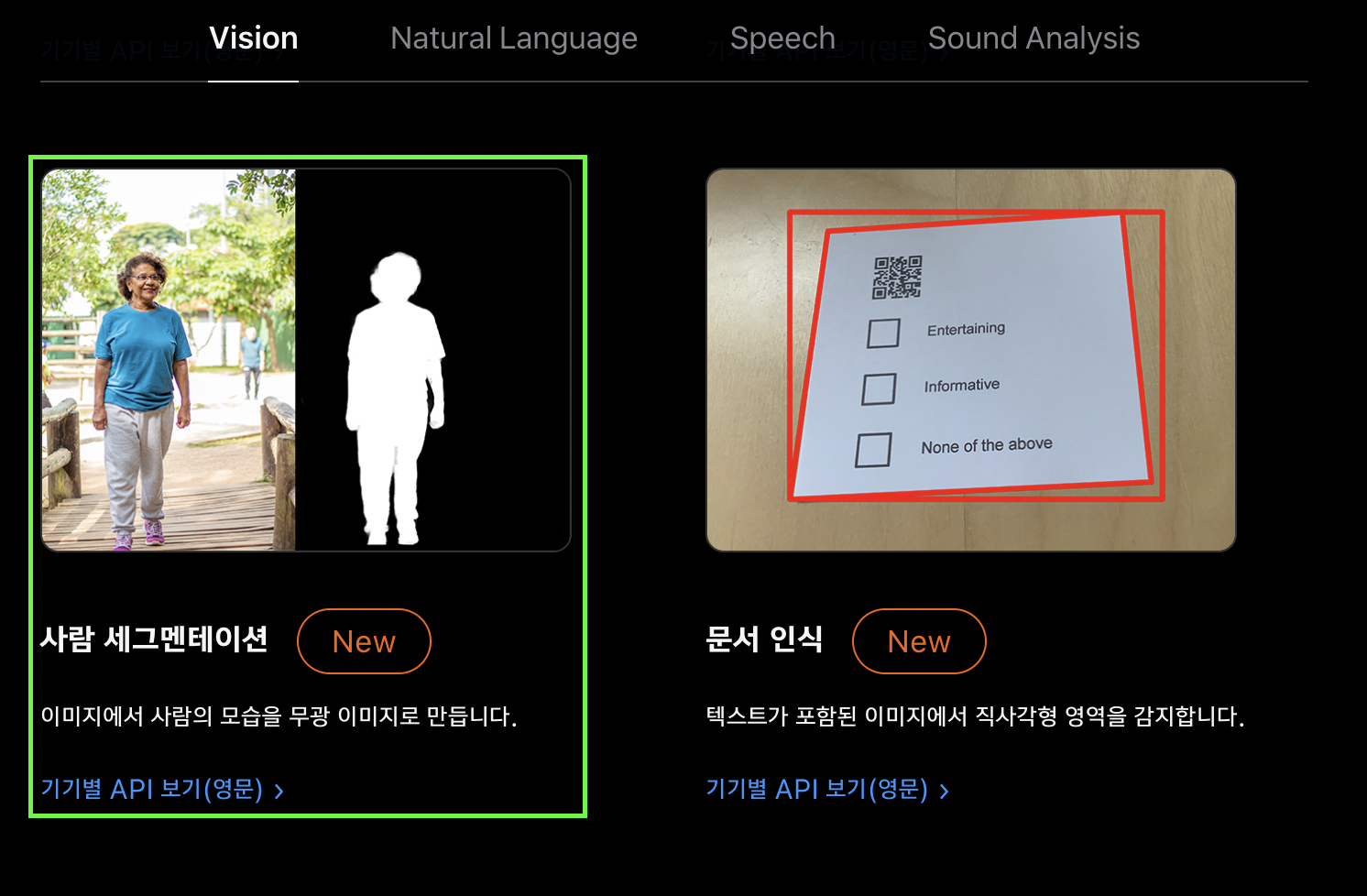
추가로, Lift subjects from images in your app | WWDC2023영상을 참고해 보면 사람뿐만 아니라 다른 라벨(물체)의 경우에도 instance Segmentation을 할 수 있을 것 같습니다.

DeeplabV3
지금까지 Apple에 내장된 Segmentation기술의 변천사를 살펴보면 다음과 같습니다.
↓
[iOS16] 누끼기능 탑제
↓
[iOS17] Instance Segmentation, 누끼확장기능
사실 iOS15 Person Segmentation API가 생기기 이전에 Apple Developer에서는 이미 ‘DeeplabV3’ CoreML모델을 공개했었습니다.
ML Models | Apple Developer를 살펴보면 Segmentation 모델로 공식적으로 등록되어 있는 ‘DeeplabV3’모델을 확인해볼 수 있습니다.
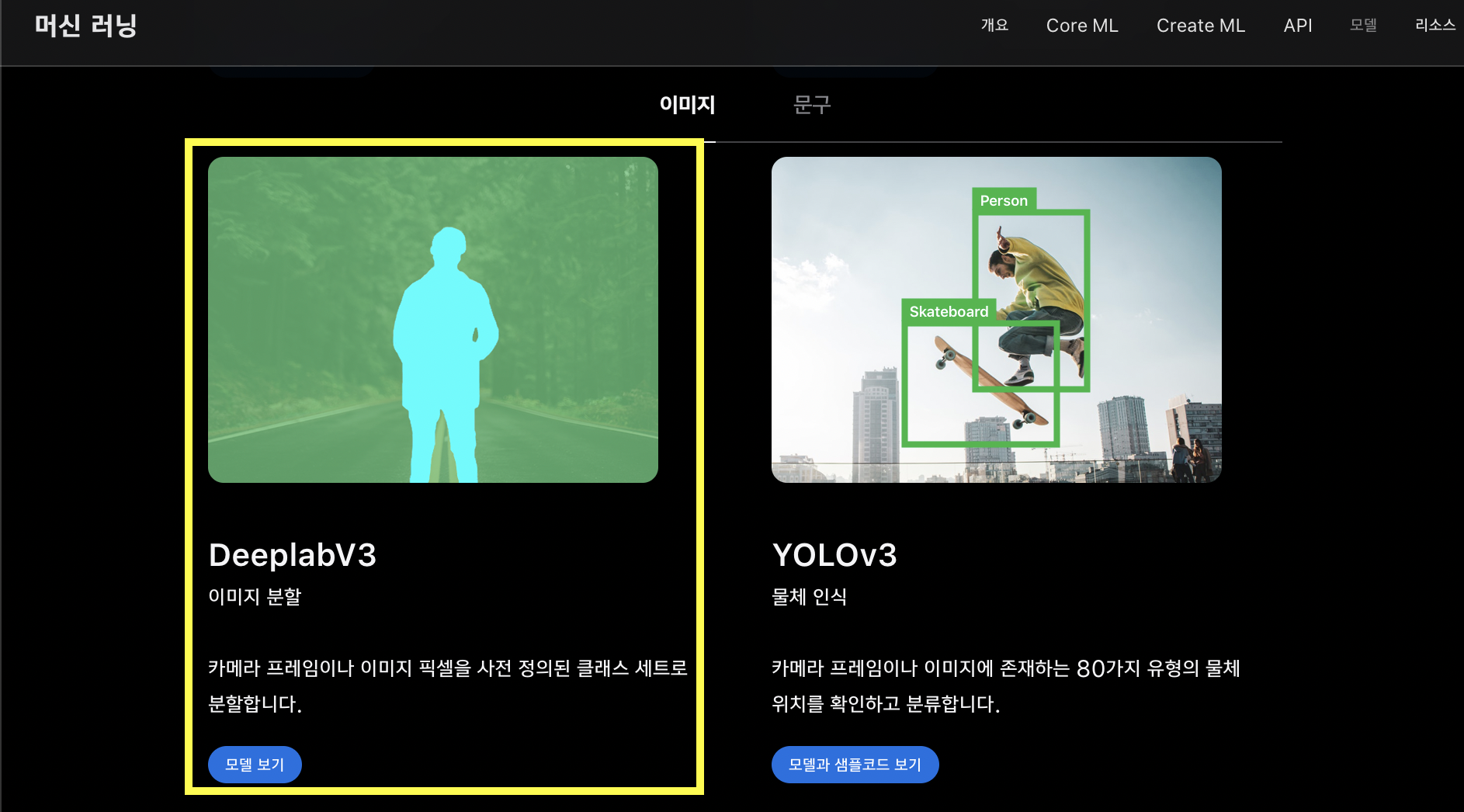
정확히 어느시점인지 알 수 없지만, CoreML이 iOS11(A11칩셋)때 나온 점과, DeeplabV3가 구글에서 공개된 날짜가 2017년인 것을 보면, Apple의 DeepLabV3 MLModel도 이맘때 쯤 공개되지 않았나 추측하고 있습니다.
Vision API가 AI모델 기능을 제공할 수 있는 것도 내부적으로
DeeplabV3모델의 기능을 좀 더 최적화하고 Person(사람)의 Segmentation기능만 분리해서 경량화한 모델이 Vision API 내부로 내장된 것이 아닐까 추측하고 있습니다. (독자적인 모델 일지라도 분명히 영향을 받았을 것 입니다. 하지만 이 부분에 대해서는 중요하지 않을 뿐더러 추측일 뿐이니 가볍게 넘어가주세요..ㅎㅎ)
DeepLabV3 사용해서 PersonSegmentation 기능 구현하기
VisionAPI에서 제공하는 경우 Person Segmentation기능을 사용하면, 굳이 DeepLabV3모델을 사용할 필요가 없을 정도로 사용성이 정말로 좋습니다.(Person[사람] 라벨링 한정)
하지만 VisionAPI의 Person Segmentation기능을 사용하기 이전에, DeepLabV3모델을 사용하는 방법에 대해 알아보도록 하겠습니다.
DeepLabV3?
왜 굳이 VisionAPI에서 제공되는 기능을 어렵게 MLModel을 사용하냐고 할 수 있지만, 사실 Vison API에 내장되는 MLModel의 경우 한정적입니다. (Apple에서 iOS 혹은 VisionOS, 더나아가 애플카..에 쓸예정인 AI모델에 대한 기능들만 내장되는 느낌입니다. 그중에서도 비교적 경량화된 모델)
때문에, 커스텀된 모델 혹은 다양한 모델들을 사용하기 위해서는 MLModel파일들을 직접 다뤄서 구현할 수 밖에 없습니다. CoreML프레임워크를 이용해서 DeepLabV3모델을 다루는 방법을 알아두면, 추후에 Vision관련 모델을 다룰 때 도움이 될 것 이라고 생각합니다.
.mlmodel파일 살펴보기
본격적으로 .mlmodel을 사용하기에 앞서 해당 파일을 눌러 파악해볼 필요가 있습니다.
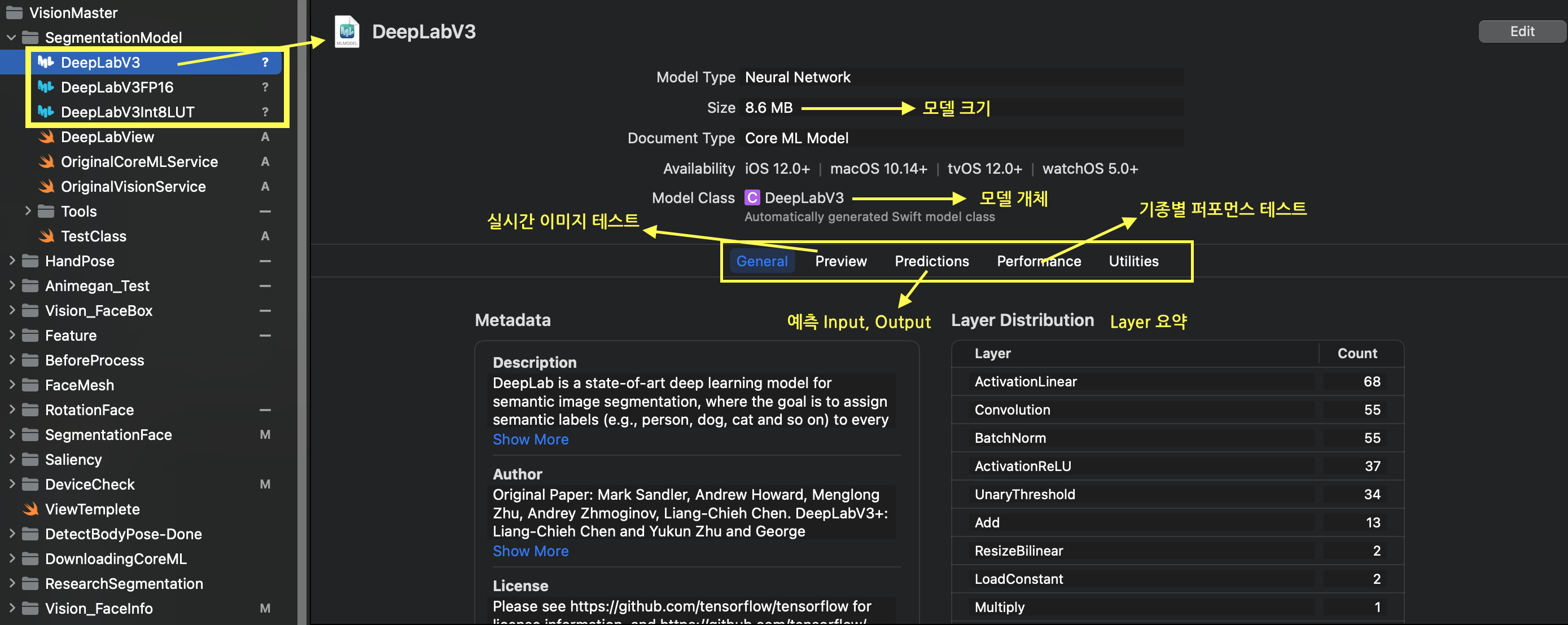
해당 MLModel파일을 프로젝트에 가져오면 Xcode내에서 자세한 정보를 얻을 수 있습니다.
Metadata의 경우 ‘Edit’기능을 이용하여, 모델개발자가 직접 커스텀하여 작성해줄 수 있습니다. 모델에 대한 설명 뿐만아니라, “실시간 이미지 테스트”, “기종별 퍼포먼스 테스트”등도 해당 화면내에서 진행이 가능합니다.
우선, 모델을 사용하기 위해 필요한 정보를 알아보도록 하겠습니다.
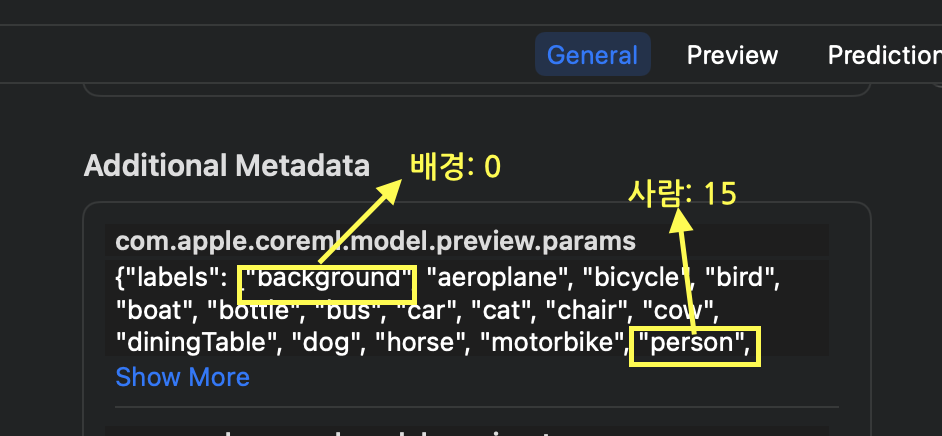
Metadata의 아래쪽을 보면 DeepLabV3가 라벨링할 수 있는 종류들이 나열되어 있습니다.
Person Segmentation기능을 만들기 위해서는 Person라벨만 알면 됩니다.
직접 모델을 사용하면 알 수 있지만, 해당 인덱스 순번과 일치하여 Person(사람)의 영역은 구분자로 15을 출력하게 됩니다.
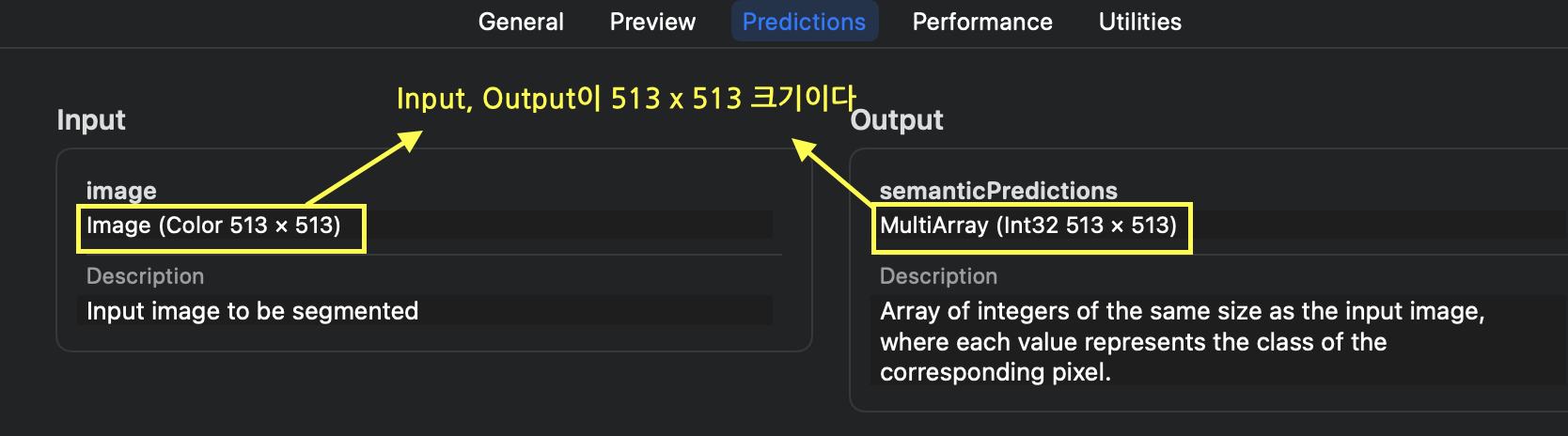
Predictions탭이 사실상 가장 중요한데, Input, Output에 대한 정보가 적혀 있습니다.
Input, Output의 경우 개발자가 모델을 사용할 때 해당정보를 이용해서 전처리, 후처리를 해야되기 때문에 반드시 파악 해야 되는 정보입니다.
DeepLabV3의 경우 Input, Output 이미지의 크기가 513x513으로 고정되어 있음을 알 수 있습니다.
Layer Distribution에 대해서도 적혀 있는데, AI모델을 추론하기 위해 거치게 되는 각각의 Layer에 대한 요약입니다.
보통 Layer의 수가 적을 수록 계산량이 줄어, 추론의 속도가 증가하게 됩니다.
너무 적으면 성능이 저하되고, 너무 많으면 과적합이 될 수 있기 때문에 쓰임에따라 적절한 Layer의 수의 모델을 만드는 것이 중요합니다.
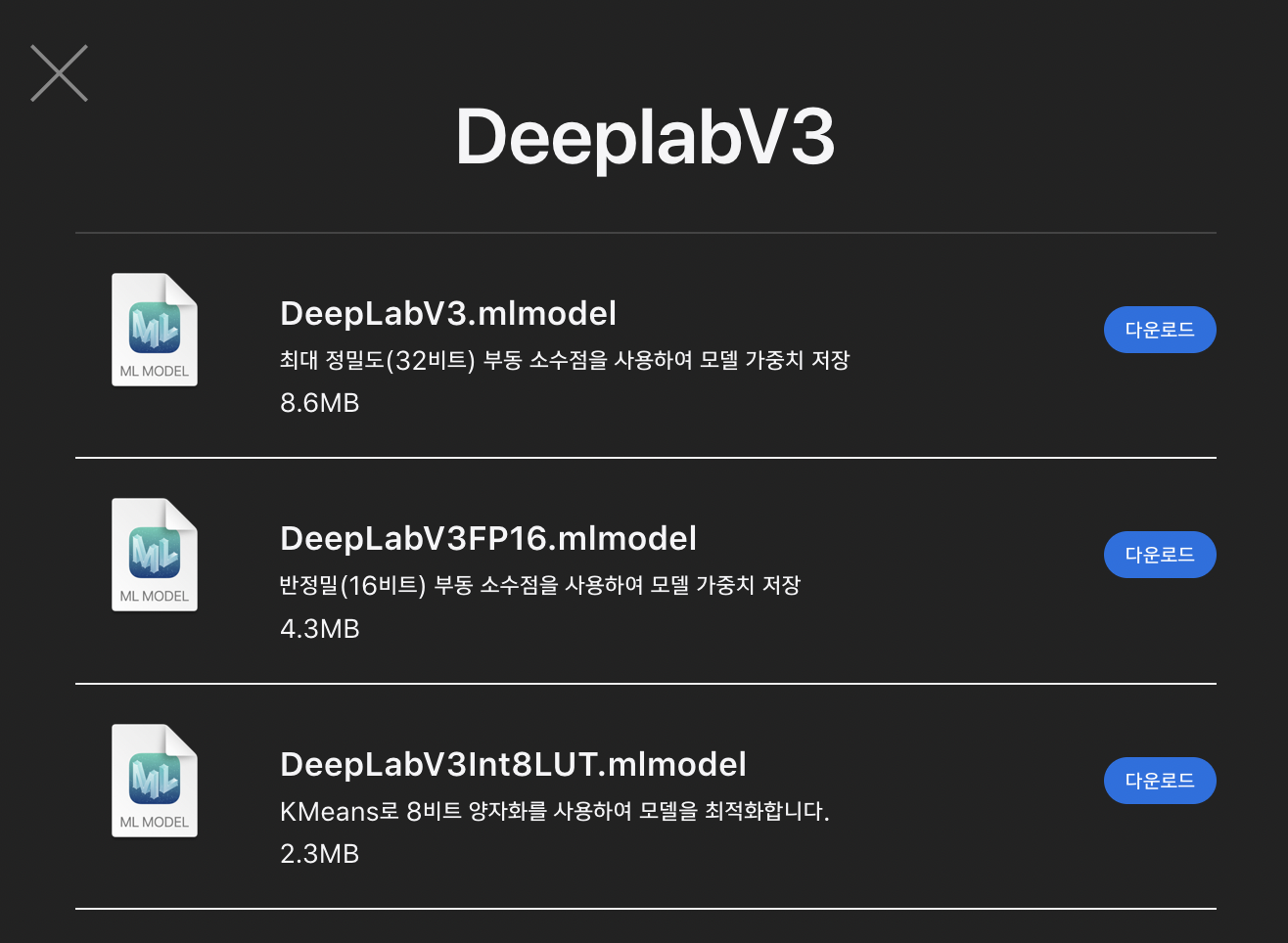
현재 Apple에서 제공하는 DeepLabV3모델의 경우 32bit-Float, 16bit-Float, 8bit-Int 모델이 있는데, 16bit-Float의 모델의 경우 32bit-Float모델 대비 용량은 1/2로 감소했지만, 단순히 가중치(정밀도)만 줄어들었을뿐 Layer가 줄어들지 않았습니다.
때문에 두 모델을 직접사용하여 비교해보면 추론 속도의 차이가 없습니다.
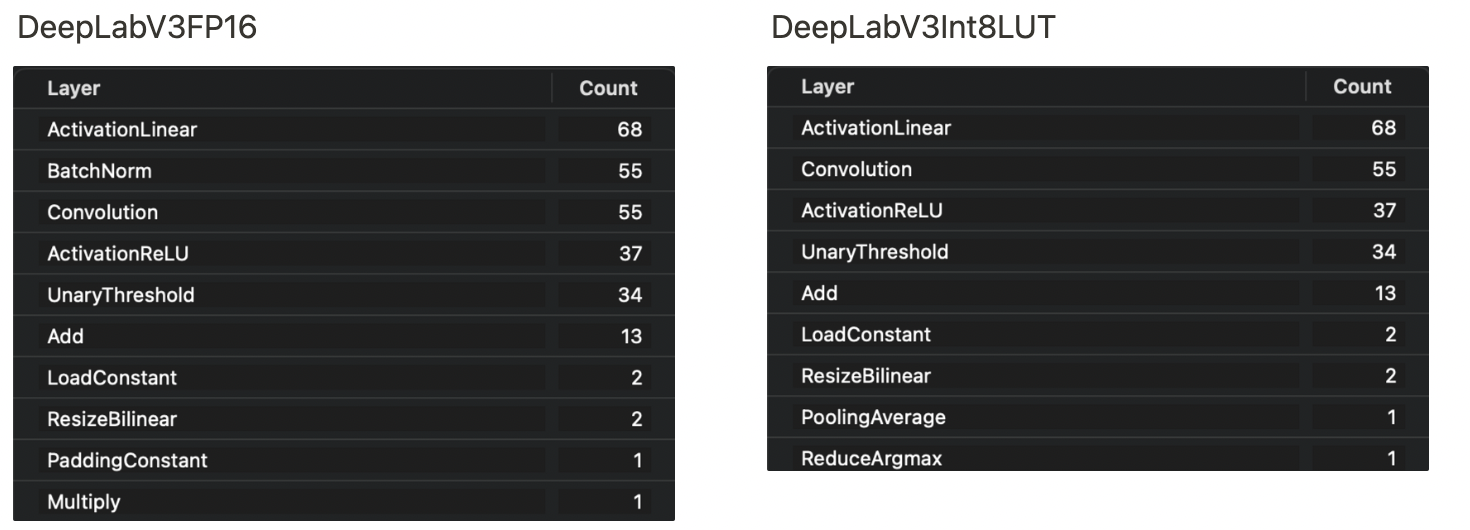
반면 8bit-Int 모델의 경우 추가로 “양자화”라는 최적화까지 진행한 모델입니다. Layer 설명을 비교해보면 알 수 있듯이 8bit-Int모델의 Layer가 더 적음을 알 수 있습니다.
용량감소뿐만 아니라, 더 빠른 속도록 추론을 할 수 있게 됩니다.
이러한 mlmodel의 최적화에 대한 내용에 대해 자세히 알고 싶다면 다음의 WWDC2023영상을 참고하면 좋을 것 같습니다. Use Core ML Tools for machine learning model compression | WWDC2023
DeeplabV3 메서드 살펴보기
.mlmodel파일을 Xcode에 추가하면 CoreML프레임워크에서 자동으로 해당 모델에 관한 생성자 및 추론 메서드들을 생성해줍니다.
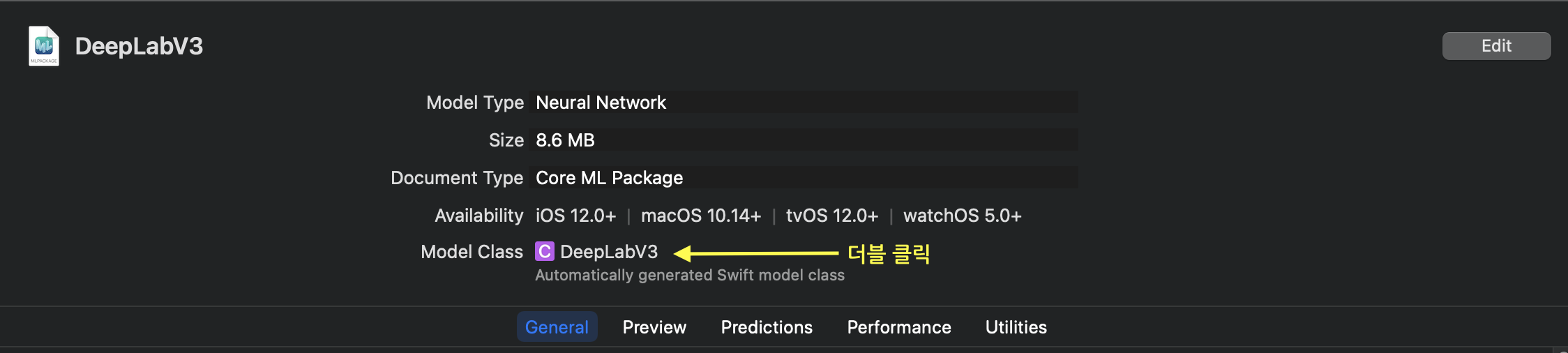
오버로드된 다양한 생성자 및 추론메서드들이 존재하며, 심지어 iOS15부터는 async-await로 모델을 로드할 수 있는 메서드도 있습니다.
async-await 비동기 로드 메서드

CPU 및 GPU를 사용하면 모델 생성 및 로드의 이점을 얻을 수 없지만, Neural Engine을 사용하면 모델을 한번 로드(생성)을 하면 해당 모델을 재사용하여 추론하는 능력이 압도적으로 빨라집니다.
반면 경험상 아직 모델을 한번에 한개씩 밖에 로드를 할 수 없다는 점에서 살짝 아쉬운점이 있습니다.
다양한 종류의 추론(prediction)메서드
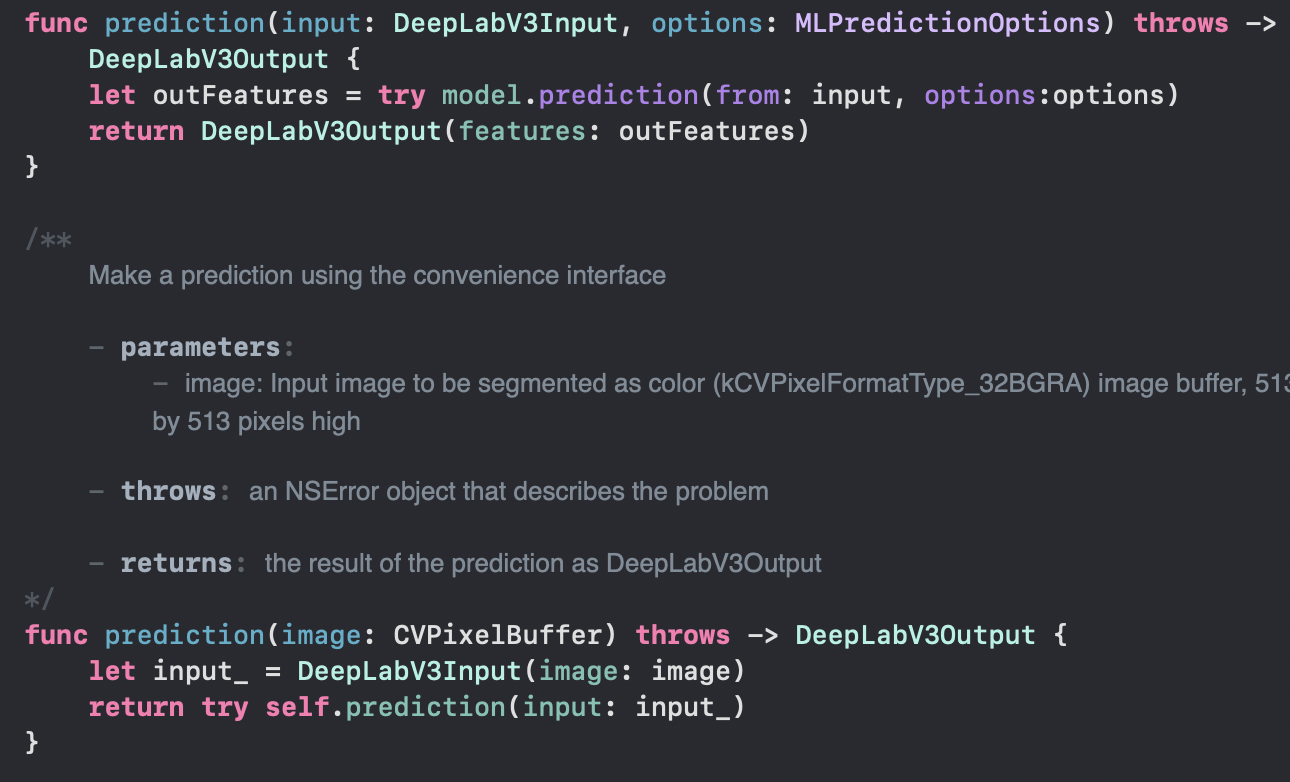
생성자 및 로드 메서드 뿐만 아니라 추론(prediction)메서드도 다양하게 제공합니다.
되도록이면 CVPixelBuffer대신 DeepLabV3Input타입을 이용해서 추론 하는 방법을 추천드립니다.
DeepLabV3Input타입을 생성할때도 역시 CVPixelBuffer를 이용해서 생성하는 방식보다 convenience 생성자를 이용해서 생성하는 방식을 추천합니다.
다양한 종류의 DeepLabV3Input 생성자
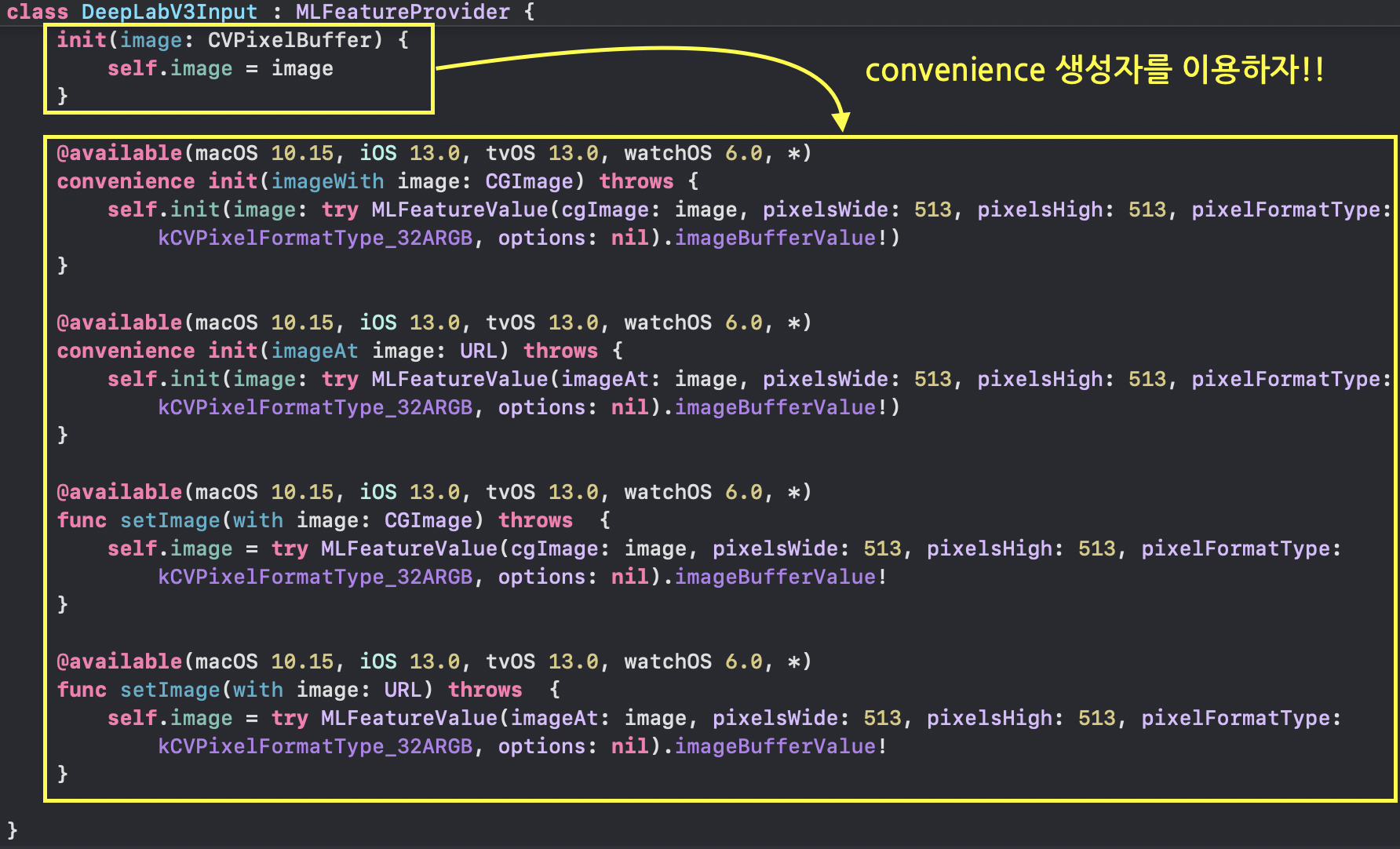
CVPixelBuffer에 대한 내용은 [Swift] CVPixelBuffer | kirkim 포스트에서 다뤘던 적이 있는데, 결론적으로 “CVPixelBuffer를 만드는데 관리해야할 요소들이 많기 때문에, 되도록이면 Swift에서 제공해주는 CVPixelBuffer만 사용하자”였습니다.
심지어 DeepLabV3에 사용할 수 있는 Input이미지의 크기가 513x513으로, CVPixelBuffer를 해당 크기로 직접 만들어 주어야 합니다.
하지만 DeepLabV3Input의 convenience 생성자들을 사용하면 이러한 불필요한 이미지 설정들을 알아서 처리 해줍니다.
batch 추론(prediction) 메서드
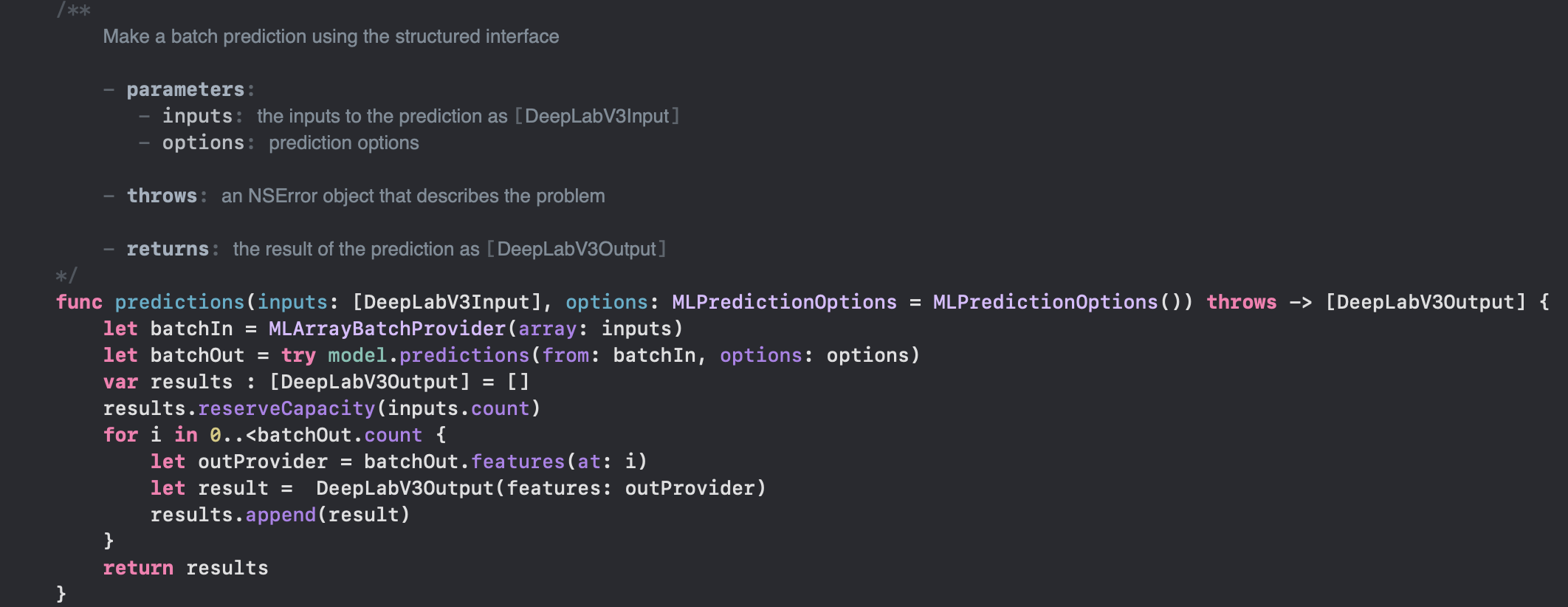
MLModel을 직접최적화하는 방법과 별개로 앱쪽에서 모델을 사용함에 있어서 빠르게 추론할 수 있는 방법으로 batch 추론을 하는 방법이 있는데, 이러한 batch 메서드도 CoreML프레임워크가 자동으로 만들어서 제공해줍니다.
이러한 최적화된 메서드를 잘 활용하면 여러모델을 동시에 추론하는데 도움이 될 것 같습니다.
DeepLabV3Output 클래스
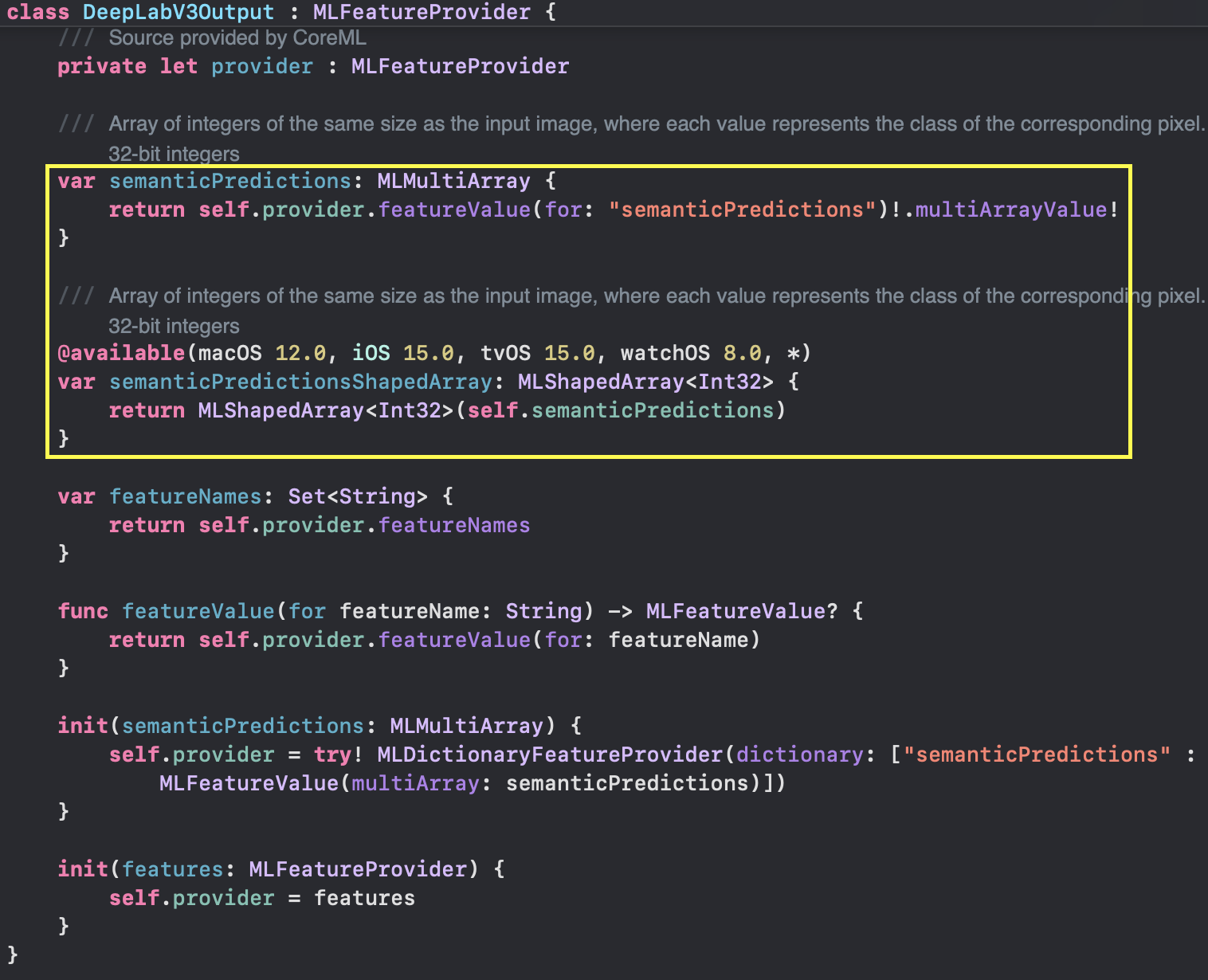
DeepLabV3모델은 추론(prediction)의 결과값으로 DeepLabV3Output을 얻을 수 있습니다. DeepLabV3Output내부변수중 MLMultiArray 혹은 MLShapedArray
DeepLabV3.mlmodel MultiArray shape
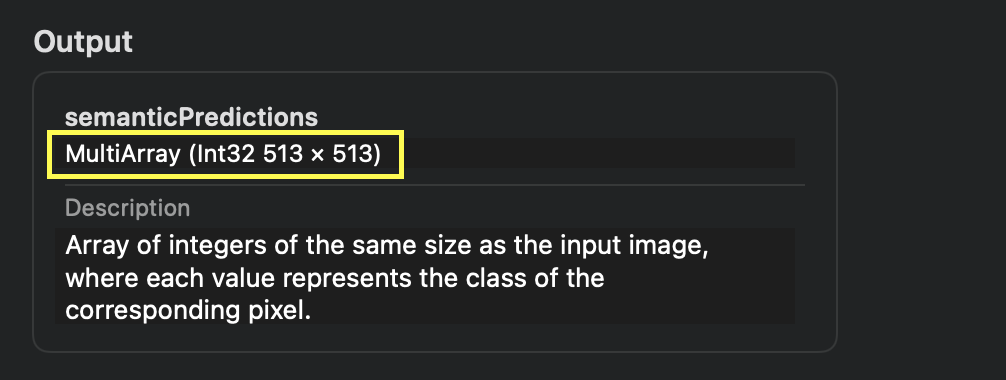
CoreML 프레임워크의 역할은 여기까지입니다. 이렇게 얻게된 MultiArray타입을 후처리하여 사용하면 됩니다.
MultiArray는 다양한 형태로 만들어질 수 있는데, DeepLabV3처럼 (Int32 513 x 513)로 2차원형태로 반환해주는 모델은 아주 친절한편입니다.
어느 facemesh.mlmodel MultiArray shape
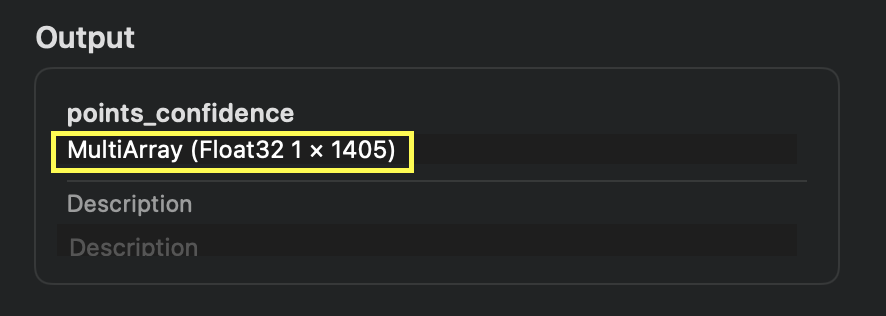
위의 이미지의 모델을 보면 MultiArray shape가 (1x1405)인데, 1차원 배열인척하는 3차원 배열입니다. MultiArray의 구조가 이 처럼 기괴할 수 있습니다. 어쩌면 AI개발자들은 이미 익숙한 약속된 구조일 수도 있습니다. 때문에 앱개발자로써 ML모델을 사용하기 이전에 모델에 대해서 제대로 파악할 필요가 있습니다.
모델의 Output타입에 대해 파악한 뒤에, 앱에서 사용할 수 있게 후처리가 필요합니다.
이 부분에 대해서도 약간의 어려움이 따를 수 있는데, 파이썬에서 numpy라는 패키지를 사용하면 쉽게 3차원배열로 만들어 사용할 수 있지만, Swift에서는 해당 메서드를 직접 만들어서 사용해야하는 일이 생길 수도 있습니다. (Accelerate패키지와 같이 Swift내장 패키지에서 제공해줄 수도 있는데, 제가 못찾은 것 일 수도..)
이런 기괴한 구조(3차원배열을 1차원형태로 나열된 구조)는 기계학습에 효율이 좋다 등등 이유가 있는 것 같은데, iOS개발자인 저는 여기까지만 알아보도록 하겠습니다…

다시 DeepLabV3Output 타입으로 돌아오면 MLMultiArray 혹은 MLShapedArray를 사용하여 기호에 맞게 후처리하여 사용하면 됩니다.
MLShapedArray타입이 비교적 최근인 iOS15부터 지원되는 타입입니다.
MLMultiArray 혹은 MLShapedArray
아직 이 두타입을 구분하고 쓸정도로 사용한 경험이 없기 때문에, MLMultiArray타입을 이용하도록 하겠습니다. 확실한 것은 이 두타입 모두 앱에 이미지(UIImage, CIImage, CGImage등등..)로 사용하기에는 그닥 좋지 못한 타입인 것 같습니다.
맥도날드에 간 하성킴 만들기(DeepLabV3를 이용한 누끼)
지금까지 .mlmodel과 CoreML프레임워크에서 지원해주는 메서드들에 대해 알아봤습니다.
이제 이러한 기능들을 이용해서 “맥도날드에 간 하성킴”을 만들어 보겠습니다.
기본 원리는 김하성(사람)의 누끼를 딴 뒤 맥도날드배경(background)사진에 붙이면 됩니다.
DeepLabV3모델을 사용하여 배경을 바꾸는 코드
func process(from image: UIImage, to background: UIImage) -> UIImage? {
let configuration = MLModelConfiguration()
guard let model = try? DeepLabV3(configuration: configuration),
let cgImage = image.cgImage,
let deepLabV3Input = try? DeepLabV3Input(imageWith: cgImage) else {
return nil
}
guard let deepLabV3Output = try? model.prediction(input: deepLabV3Input) else {
return nil
}
let mlmultiArrayOutput = deepLabV3Output.semanticPredictions
// Chat-GPT가 만들어준 MLMultiArray to CIImage 메서드 사용
guard let maskImage = createCIImage(from: mlmultiArrayOutput) else {
return nil
}
// CIFilter.blendWithMask()를 이용한 이미지 합치기
guard let mergedImage = mergeImage(input: image, background: background, mask: maskImage) else {
return nil
}
return mergedImage
}
CoreImage.CIFilterBuiltins 프레임워크의 CIFilter.blendWithMask() 필터기능을 사용하면 누끼마스크, 이미지, 배경이미지를 이용하여 이미지를 합칠 수 있습니다. DeepLabV3추론으로 얻은 MLMultiArray를 누끼마스크(CIImage)로 만들어 주는 메서드(createCIImage)는 Chat-GPT를 이용해서 만들었습니다.
이럴때 쓰라고 있는게 Chat-GPT이지 아닌가 싶습니다..
Chat-GPT에게 도움 요청
DeepLabV3모델을 이용한 맥도날드에 간 하성킴 만들기

VisionAPI + DeepLabV3모델 사용해서 구현하기
VisionAPI는 Vision관련 AI기능 뿐만아니라, Vision관련모델을 다루는데 도움을 주는 메서드들도 제공해줍니다.
우선 이런한 VisionAPI제공 메서드를 사용하지 않고 CoreML 프레임워크만을 사용하여 PersonSegmentaion을 구현해보겠습니다.
func process(from image: UIImage, to background: UIImage) -> UIImage? {
let configuration = MLModelConfiguration()
guard
let model = try? MLModel(
contentsOf: DeepLabV3.urlOfModelInThisBundle,
configuration: configuration
),
let coreMLModel = try? VNCoreMLModel(for: model),
let inputCGImage = image.cgImage
else {
return nil
}
let request = VNCoreMLRequest(model: coreMLModel)
let requestHandler = VNImageRequestHandler(cgImage: inputCGImage)
do {
try requestHandler.perform([request])
} catch {
return nil
}
guard let result = request.results?.first as? VNCoreMLFeatureValueObservation,
let multiArray = result.featureValue.multiArrayValue
else {
return nil
}
// Chat-GPT가 만들어준 MLMultiArray to CIImage 메서드 사용
guard let maskImage = createCIImage(from: multiArray) else {
return nil
}
// CIFilter.blendWithMask()를 이용한 이미지 합치기
guard let mergedImage = mergeImage(input: image, background: background, mask: maskImage) else {
return nil
}
return mergedImage
}
순수 CoreML 프레임워크가 제공해주는 코드보다 더 복잡한 것 같은 기분이 들지만,
VisionAPI기능을 이용하면, 같은 VNObservation 타입의 모델들에 대해 재사용코드를 구현하기가 좋고, MLModel혹은 Vision모델과 조합해서 사용할 수 있는 기능 등등.. 다양한 기능을 제공하고 리소스 관리 및 다양한 옵션들을 통해 효율적으로 모델을 사용할 수 있도록 도와줍니다.
VisionAPI내장 모델 사용하기(VNGeneratePersonSegmentationRequest)
iOS15부터, Segmentation모델이 VisionAPI에 내장되었습니다. 물론, Person(사람)에 대한 Segmentation모델이지만 Swift 개발자 입장에서 모델을 다루기가 엄청나게 편해졌습니다.
func makePersonSegmentationMask(by baseImage: UIImage) -> CIImage? {
let request = VNGeneratePersonSegmentationRequest()
request.usesCPUOnly = true // CPU만 사용해서 처리(default: neural engine, cpu, gpu 조합 처리)
request.qualityLevel = .fast // 퀄리티보다 속도 우선
request.outputPixelFormat = kCVPixelFormatType_OneComponent8 // 8비트 출력
guard let baseCGImage = baseImage.cgImage else {
return nil
}
let handler = VNImageRequestHandler(cgImage: baseCGImage, options: [:])
do {
try handler.perform([request])
guard let maskObservation = request.results?.first else {
return nil
}
return CIImage(cvPixelBuffer: maskObservation.pixelBuffer)
} catch {
return nil
}
}
Vision에 내장된 PersonSegmentation모델을 사용하면 해당 모델에 특화된 옵션들을 쉽게 커스텀하여 사용할 수 있습니다.
예를들면 퀄리티 vs 속도 의 trade-off사항을 조절하여 사용할 수 있습니다.
qualityLevel(.fast, .balanced, .accurate

또한 VisionAPI에 내장된 모델을 사용하는데 있어서 가장 좋은 점은 iOS앱에서 UI적으로 사용하기에 까다로웠던 MLMultiArray, MLShapedArray 타입 대신 CVPixelBuffer타입으로 결과를 반환해 준다는 것 입니다. 때문에 별도의 후처리 없이 CIImage로 만들어서 사용할 수 있습니다.
Vision API | Apple Developer를 살펴보면 Person Segmentation API 외에도 Vision API에 내장된 AI기능들이 많이 있습니다.
Vision API에 내장된 모델들은 Apple에서 경량화 및 최적화가 되어 있으며, 앱개발자 입장에서 사용하기가 쉽도록 처리가 되어 있기 때문에, MLModel을 사용하기 이전에 Vision API 사용을 먼저 고려하는 것도 좋은 방법인 것 같습니다.
참고링크
What’s new in VisionKit | WWDC2023
Lift subjects from images in your app | WWDC2023
Vision API | Apple Developer
ML Models | Apple Developer
Top 10 Deep Learning Algorithms in Machine Learning [2023] | ProjectPro
Use Core ML Tools for machine learning model compression | WWDC2023
Improve Core ML integration with async prediction | WWDC2023
[Swift] CVPixelBuffer | kirkim
Tune your Core ML models | Apple Developer
VNGeneratePersonSegmentationRequest | Apple Developer
qualityLevel | Apple Developer

개발공부 블로그입니다.