[iOS] Neural Engine | Apple
NPU(Neural engine)가 주목받는 이유
AI기술이 빠르게 발전하면서 점점 우리 생활속에 빠르게 녹아들고 있습니다.
하지만 점점 생활 속에서 요구하는 AI기술수준이 높아짐에 따라 모델들을 감당하기 위한
비용이 증가하는 요인은 다음과 같습니다.
- 모델의 크기(가중치)가 커져 계산량이 많아짐
- 모델사용량 증가
모델 크기 및 사용량 증가의 예시로는 다음과 같습니다.
- ChatGPT모델중 GPT-3도 굉장히 큰 언어 모델(LLM)인데, 올해 3월에 공개한 GPT-4의 경우 GPT-3보다 100배이상 큰 모델
- 비교적 무거운 모델인 Stable-diffusion을 요즘에는 영상 프레임단위로 변환해주는 Tool도 있습니다.(한번 사용시 모델을 수백번정도 사용)
- Yolo모델중 Yolo3의 경우 80가지 물체를 감지할 수 있는데, 감지할 수 있는 물체의 가지수가 증가하면, 그만큼 가중치값이 증가하게 되어 모델의 크기가 점점 커지게 됩니다.
비용 증가는
단편적으로 봤을때, 비용을 줄이기 위한 방법은 크게 2가지 입니다.
- 모델의 크기를 줄이기(최적화)
- 저렴한 하드웨어 사용
이 중 두번째 해결방법으로 NPU사용이 될 수 있습니다.
그 이유는 NPU는 GPU대비 다음과 같은 장점이 있기 때문입니다.
- 전력 효율이 좋다
- 구조가 단순하기 때문에 부품 및 공간차지면에서 비용 절감 가능
- 신경망 연산 특화로 성능이 좋다
이처럼 NPU는 단순히 저렴할 뿐만 아니라 성능도 좋습니다.
이것이 NPU가 AI기술이 발전함에 따라 점점 더 주목을 받고 있는 이유라고 생각합니다.
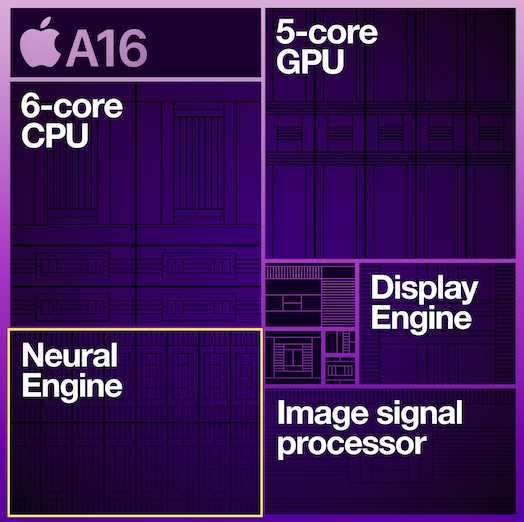
Neural engine
Neural engine은 Apple의 NPU(AI반도체, 딥 러닝 가속엔진) 이름입니다.
(구글: TPU, 테스라: D1, 그래프코어: IPU.. 등등 각회사마다 AI반도체 명칭이 제각각)
A11 Bionic칩(iphoneX, iphone8)부터 내장되기 시작했으며, 이를 기반으로 iphoneX부터는 Neural engine을 이용한 FaceID 식별기능이 생기기도 했습니다.
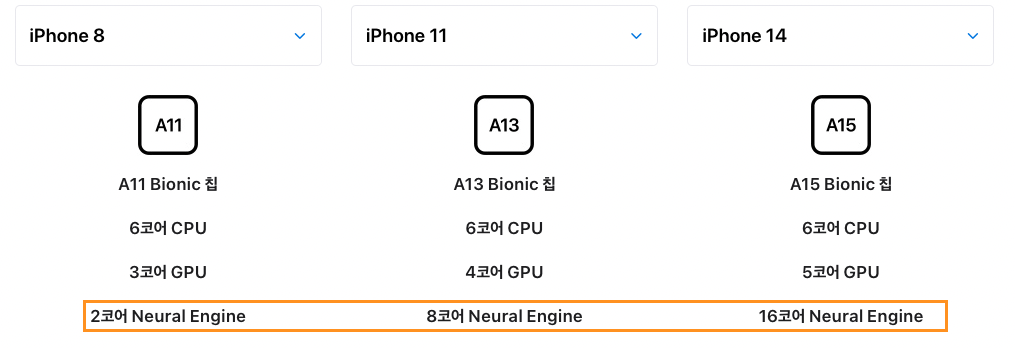
A11칩셋부터 A15칩셋까지의 변화를 살펴보면 CPU, GPU보다 neural engine의 성능 및 코어 수의 증가폭이 월등히 앞서고 있습니다.
2017년 구글 pixel과 애플 iphone을 시작으로 AI반도체를 온디바이스화하는 회사가 증가하고 있는데, 그만큼 AI기술이 사용자 경험에 있어서 빠질 수 없는 요소로 자리잡고 있는 것 같습니다.
NPU(AI반도체, 딥 러닝 가속엔진)
사실 NPU가 할 수 있는 기능은 CPU, GPU로도 처리가 가능합니다.
GPU가 할 수 있는 일을 CPU가 할 수 있는 것과 같은 맥락인데,
GPU는 그래픽작업에 특화된 반도체라면, NPU는 AI알고리즘패턴을 계산하는데 특화된 반도체입니다.
단순히 기능으로만 포함 관계를 따지자면 NPU ⊂ GPU ⊂ CPU 가 될 것 같습니다.
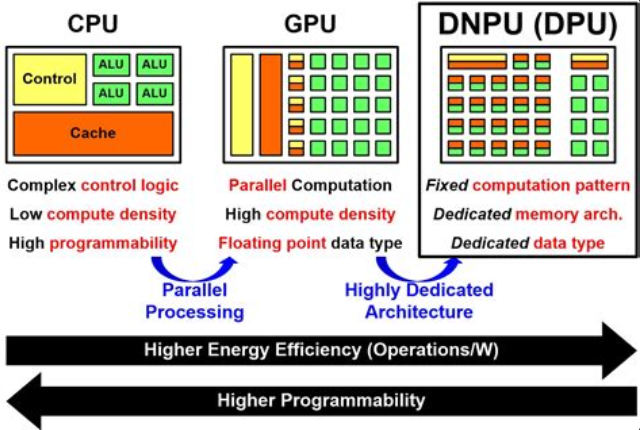
구조적으로 살펴보면 NPU의 경우 각각의 ALU(산술 논리 장치)에 캐시메모리가 배정되어 있음을 볼 수 있습니다.
이러한 구조를 통해 사람의 뇌와 유사한 방식으로 데이터를 처리하여, 신경망을 빠르고 효율적으로 처리할 수 있습니다.
하지만 특정 신경망(AI알고리즘)만 가능하며, Neural Engine의 경우 대표적으로
- CNN(Convolutional Neural Network)
- RNN(Recurrent Neural Network)
- LSTM(Long Short-Term Memory)
- Transformer
등등을 포함하고 있습니다.
또한 NPU는 신경망을 학습한 후, 새로운 데이터를 신경망에 입력하여 신경망이 출력하는 결과를 얻는 추론을 수행하는 데에도 좋습니다.
Neural Engine(NPU) 한계
- 범용적이지 않다.
CPU, GPU만큼 범용적이지 않기 때문에 아직 클라우드, 서버에서의 점유율은 높지 않습니다. - 디바이스적인 한계
전력, 메모리적인 한계 때문에 대규모 모델을 돌리기가 힘들다. Chat gpt같은 LLM모델 혹은 Stablediffusion등등..(Stablediffusion모델은 곧 호환 될 수도?) - 학습보다는 추론에 특화됨
개인적으로 사용했을 때 아직 온디바이스 학습에는 적합하지 않은 것 같습니다. 위에서 언급한 전력, 메모리적인 한계 때문인 것도 있으며 아직까지 학습의 경우 GPU가 더 뛰어난 성능을 보일 수 도 있는 것 같습니다. 그러나 디바이스에는 큰 모델을 학습할만큼 충분한 GPU도 없습니다. 반면 이미 만들어진 모델(.mlmodel)을 사용하여 inference(추론)성능은 좋습니다.
Neural Engine(NPU) 추론 성능

비교적 무거운 모델의 prediction성능을 CPU와 Neural engine을 사용해서 비교해봤습니다.
Neural engine의 경우 처음에 Load하는 과정이 필요하지만, Load된 이후 prediction(예측)하는 속도은 iphone13 proMax기준 CPU보다 약 14배 앞섭니다.
prediction(예측)?
CoreML을 사용하다 보면 inference(추론)단어 대신 prediction(예측)이라는 단어가 쓰입니다. (Coreml관련 메서드나 Instruments tool 모두 prediction으로 쓰임)
단순히 뜻만 비교하면 다르지만, CoreML에서 사용한 prediction(예측)의 경우 미래를 미리 예측하는 것이 아니라, 주어진 정보로부터 새로운 정보를 추론하는 것과 같기 때문에, CoreML상에서만큼은 prediction(예측)과 inference(추론)을 같은 개념으로 봐도 되지 않나 생각합니다.
우선 제가 전문적인 AI개발자가 아니기 때문에 자세한 내용이나 이유는 찾아보시는 것을 권장드립니다. (최대한 내용을 검증했지만, 저의 개인적인 사용 경험을 바탕으로 쓴내용이기 때문에 틀린 내용이 있을 수도 있습니다.)
참고 링크
인공지능 칩 | 나무위키
[기술용어] Neural Engine(뉴럴 엔진) | 방송기술저널

개발공부 블로그입니다.